연구 소개

- 연구
- 연구 소개
Extended Fusion Algorithm of A-star and Artificial Potential Field for Three-Dimensional Path Planning
- AI융합대학
- 2024-01-03
최영훈 교수의 연구실에서 인공지능 드론의 3차원 비행 경로 플래닝 기술을 연구하여 발표한 논문 "Extended Fusion Algorithm of A-star and Artificial Potential Field for Three-Dimensional Path Planning"이 국제 학술 대회인 "Joint conference of APCATS, AJSAE & AAME" 2023년 10월 호에 게재되었다.

Urban Air Mobility (UAM) has been recently getting attention due to environmental and economic reasons. This has led to research on three-dimensional path planning requiring more degrees of freedom than traditional two-dimensional path planning. Traditional path planning algorithm such as A-star and artificial potential field has focused on how to avoid collisions and how to guarantee path’s optimality. A-star algorithm is, however, hard to handle unknown obstacles, and the artificial potential field could not reach to the given destination due to local minima problem. To relieve these issues, the fusion algorithm of A-star and artificial potential field was developed.

The algorithm is, however, mainly relevant to two-dimensional path planning problems. To deal with three-dimensional path planning cases for UAM, this paper introduces an extended fusion algorithm of A-star and artificial potential field algorithms to handle three-dimensional path planning problems. To demonstrate the proposed algorithm, numerical simulations are conducted with traditional A-star and artificial potential field algorithm.
-
Amnesia as a Catalyst for Enhancing Black Box Pixel Attacks in Image Classification and Object Detection
정재훈 교수의 연구실에서 발표한 "Amnesia as a Catalyst for Enhancing Black Box Pixel Attacks in Image Classification and Object Detection" 논문이 이번 2024년 "NeurIPS (Neural Information Processing Systems)"에 게재되었다. 본 논문은 강화학습 기반의 블랙박스 픽셀 공격 기법(RFPAR)을 통해, 기존 이미지 분류 및 객체 탐지에서 사용되는 적대적 공격 기법을 개선, 적대적 이미 생성 뿐만 아니라 객체 탐지 분야에서도 혁신적인 성능 개선을 달성했다.
2024-11-17
NeurIPS는 1987년 창립된 이래 인공지능 및 기계학습 분야에서 가장 권위 있는 학회 중 하나로, 매년 전 세계 연구자들이 최첨단 연구 성과를 발표하고 토론하는 자리이다. 이번 2024년 학회에는 인공지능 학계와 업계의 관심을 받는 최신 연구들이 발표될 예정이며, 논문 선정이 매우 까다롭기로 유명하다.
논문 사이트로 이동
[Figure 1] The model architecture of RFPAR
It is well known that query-based attacks tend to have relatively higher success rates in adversarial black-box attacks. While research on black-box attacks is ac- tively being conducted, relatively few studies have focused on pixel attacks that target only a limited number of pixels. In image classification, query-based pixel attacks often rely on patches, which heavily depend on randomness and neglect the fact that scattered pixels are more suitable for adversarial attacks. Moreover, to the best of our knowledge, query-based pixel attacks have not been explored in the field of object detection. To address these issues, we propose a novel pixel-based black-box attack called Remember and Forget Pixel Attack using Reinforcement Learning(RFPAR), consisting of two main components: the Remember and For- get processes. RFPAR mitigates randomness and avoids patch dependency by leveraging rewards generated through a one-step RL algorithm to perturb pixels. RFPAR effectively creates perturbed images that minimize the confidence scores while adhering to limited pixel constraints. Furthermore, we advance our pro- posed attack beyond image classification to object detection, where RFPAR re- duces the confidence scores of detected objects to avoid detection. Experiments on the ImageNet-1K dataset for classification show that RFPAR outperformed state-of-the-art query-based pixel attacks. For object detection, using the MS- COCO dataset with YOLOv8 and DDQ, RFPAR demonstrates comparable mAP reduction to state-of-the-art query-based attack while requiring fewer query. Fur- ther experiments on the Argoverse dataset using YOLOv8 confirm that RFPAR effectively removed objects on a larger scale dataset. Our code is available at https://github.com/KAU-QuantumAILab/RFPAR.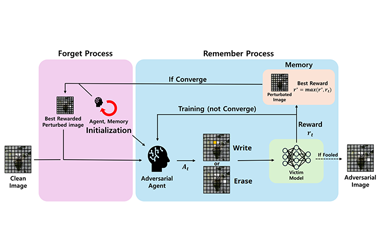
-
해군분석모델용 AI-CGF를 위한 시나리오 생성 모델 설계(I): 진화학습
지승도 교수의 연구실에서 해군 지능형 가상 군사(AI-CGF) 모의 기술을 연구하여 발표한 논문 "해군분석모델용 AI-CGF를 위한 시나리오 생성 모델 설계(I): 진화학습"이 "한국군사과학기술학회지" 12월호에 게재되었다. 본 연구는 워게임에서 인간 대신 AI를 접목한 최초의 시도에 대한 타당성을 검토한 연구로, 그 타당성이 충분히 입증되어 내년부터 보완 및 확장 연구를 추진할 예정이다.
2022-12-01
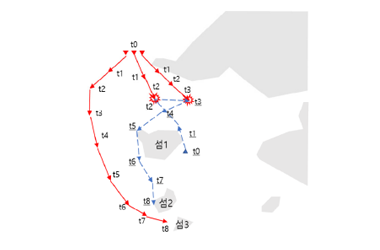
[그림 1] 전체 시스템 개요도
본 논문은 진화학습을 적용한 해군분석모델용 AI-CGF를 위한 시나리오 생성 모델을 설계하였다. 제안된 모델은 유전자 풀, 진화학습 제어기, 몬테카를로 시뮬레이션 제어기를 통해 해군분석모델에 전술 시나리오를 전달함으로써 진화학습을 시작한다. 진화 과정에서 선택, 교배, 변이의 진화 연산이 적용되었다. 총 5가지의 청군 전술 시나리오에 대하여 제안된 진화학습을 실험한 결과 전술적 가치가 높은 홍군 전술 시나리오를 생성할 수 있었다. 다만, 구성한 세력 상에서 높은 적합도가 곧바로 홍군의 승리를 의미하지는 않는 것으로 확인되었다. 그런데도 상륙전의 경우 청군의 이동 경로를 길게 가져가도록 유인함으로써 상륙 목표를 성공적으로 달성하는 고도의 전술도 확인할 수 있었다. 본 논문은 해군분석모델용 AI-CGF에 진화학습을 최초로 적용하였다. 이를 통해 인간이 설계한 청군 전술 시나리오에 대한 홍군 전술 시나리오를 자동 생성함으로써 논리적이며 수준이 높은 전술 시나리오 생성 능력을 확보할 수 있었다. 진화학습을 이용한 시나리오 생성모델은 유전 알고리즘을 통해 최적의 시나리오를 생성할 수 있다는 장점을 갖고 있으나, 학습과정에서 과도한 시간이 소요된다는 단점 또한 갖고 있다. 이를 해결하기 위해 지도 및 강화학습을 활용한 시나리오 생성 모델에 관한 연구를 후속 연구 논문에서 서술한다.